
Need help with Integer Properties, Exponents, Roots, Algebra, or Functions? You've come the right place.
Volume 2 of Master Key to the GRE is the only guide to GRE math that will teach you everything you need to know about Integer Properties, Exponents, Roots, Functions, Sequences, and Algebra.
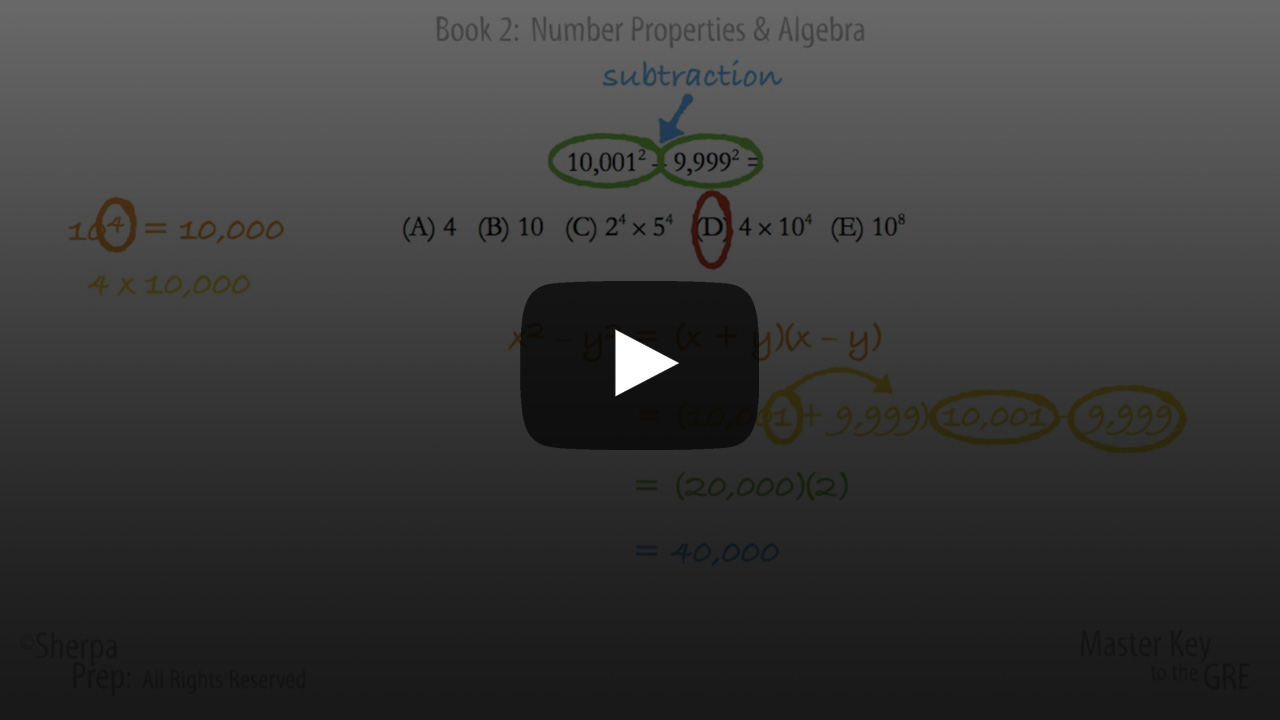
Finding Patterns



Whether you’re aiming for a perfect score or a score closer to average, mastery of the following concepts is essential.
The following concepts are either advanced or are tested only on rare occasions. If you don’t need an elite math score, don’t waste your time!
There’s no substitute for elbow grease. Practice your new skills to ensure that you internalize what you’ve studied.
Whether you’re aiming for a perfect score or a score closer to average, mastery of the following concepts is essential.
The following concepts are either advanced or are tested only on rare occasions. If you don’t need an elite math score, don’t waste your time!
There’s no substitute for elbow grease. Practice your new skills to ensure that you internalize what you’ve studied.
Whether you’re aiming for a perfect score or a score closer to average, mastery of the following concepts is essential.
The following concepts are either advanced or are tested only on rare occasions. If you don’t need an elite math score, don’t waste your time!
There’s no substitute for elbow grease. Practice your new skills to ensure that you internalize what you’ve studied.
Whether you’re aiming for a perfect score or a score closer to average, mastery of the following concepts is essential.
The following concepts are either advanced or are tested only on rare occasions. If you don’t need an elite math score, don’t waste your time!
There’s no substitute for elbow grease. Practice your new skills to ensure that you internalize what you’ve studied.
Whether you’re aiming for a perfect score or a score closer to average, mastery of the following concepts is essential.
The following concepts are either advanced or are tested only on rare occasions. If you don’t need an elite math score, don’t waste your time!
There’s no substitute for elbow grease. Practice your new skills to ensure that you internalize what you’ve studied.







© 2022 Sherpa Prep.
GRE® is a registered trademark of the Educational Testing Service™. The Educational Testing Service™ is not affiliated with Sherpa Prep or this website.

